
Large Language Models And Generative Ai Hand Book
A large language model (LLM) is a type of machine learning model that can do a lot of cool things with language. It can write text that sounds like it was written by a human, answer questions like a human would, and even translate text from one language to another. LLMs are trained using a lot of data and deep learning algorithms to understand language better. 😎
Transformer Architecture
- What is the transformer architecture? - The transformer architecture is a deep neural network architecture that was introduced in the paper “Attention Is All You Need” by Vaswani et al..
- How does the transformer architecture work? - The transformer architecture uses self-attention to compute representations of input sequences.
- What are some applications of the transformer architecture? - The transformer architecture has been used for a wide range of applications, including machine translation, text classification, and text generation.
Transformer and NN Basics
-
GPT 2 implementation from scratch by Andrej Karpathy. Video
-
GPT (Generative pretrained-transformer) created by Andrej Karpathy for education purpose. Video
Stages of building LLM

LLM starts with the pre-training stage where the model learns to predict next token given it is an auto-regressive language model. Pre-training is done an internet-scale dataset.
Scaling law
Scaling law helps to identify relationship among model parameters, dataset size and compute budget. There is a powerlaw relationship, meaning two quantities are proportional to each other based on power raised to a constant:
- Testloss vs compute budget
- Testloss vs dataset size (number of tokens)
- Testloss vs number of model parameters
Refer to Chinchilla scaling law: Training Compute-Optimal Large Language Models
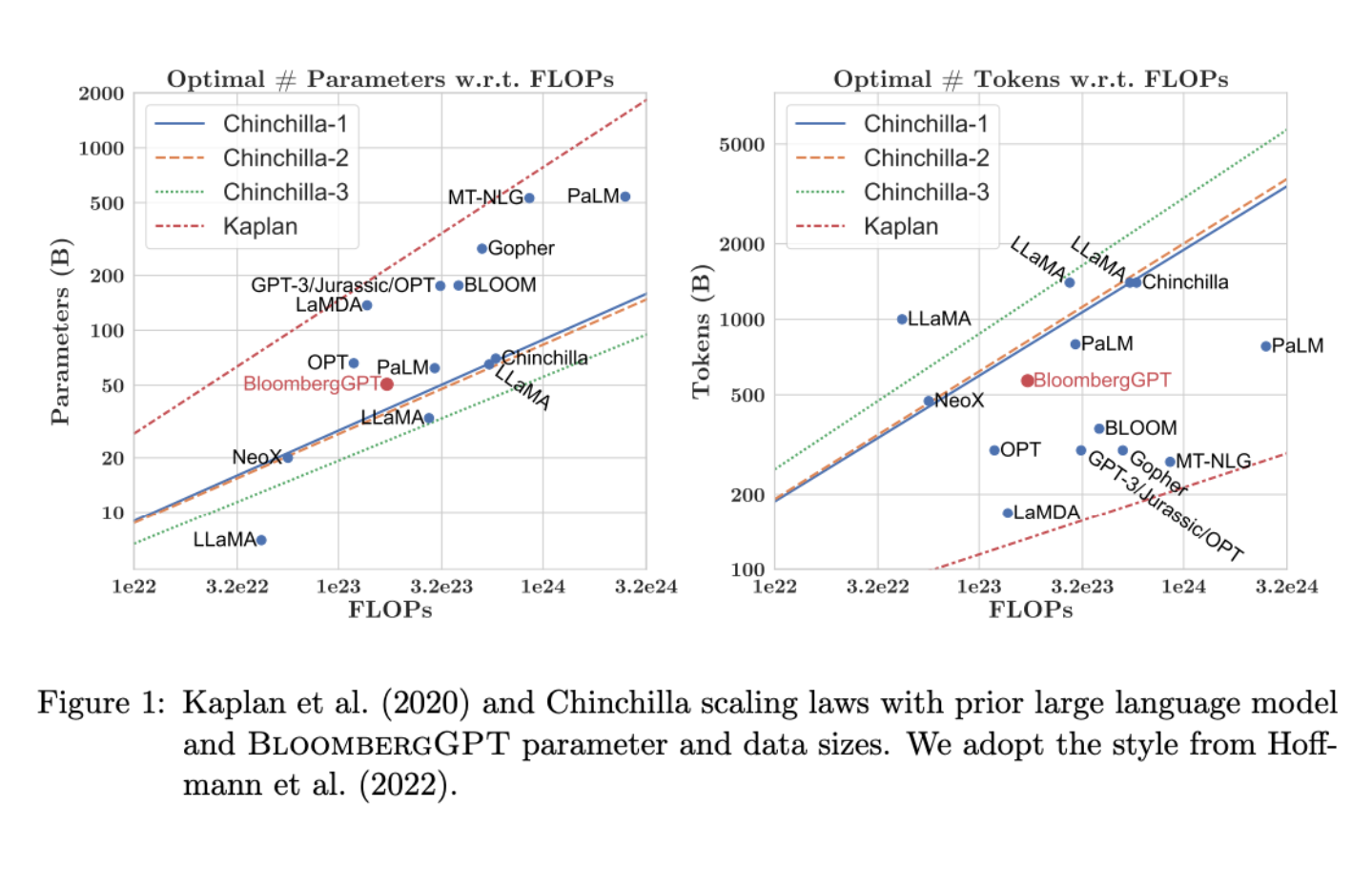
Following scaling law was followed during pretraining BloombertGPT.
Finetuning Framework for LLM
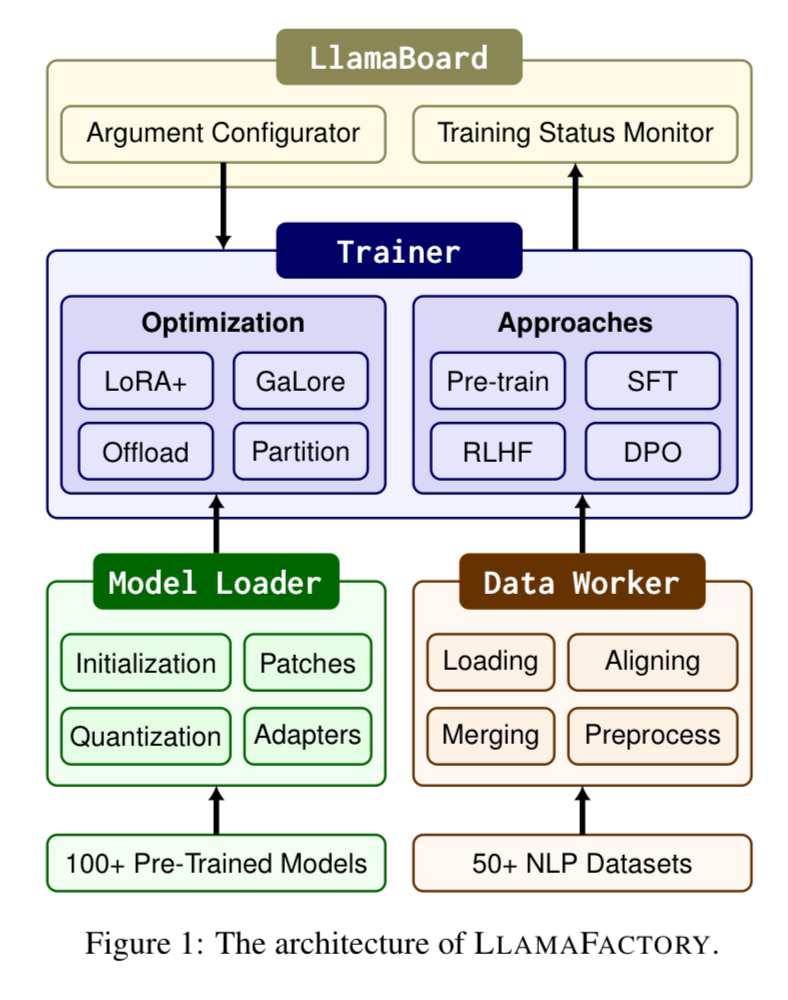
LlamaFactory provides a unified and efficient fine-tuning framework for a wide range of large language models (LLMs). By integrating various efficient training methods and supporting over 100 LLMs, LlamaFactory allows users to easily adapt these models to different downstream tasks.
Supervised Fine-Tuning
- What is fine-tuning? - Fine-tuning is the process of adapting a pre-trained language model to a specific task or domain.
- How does fine-tuning work? - Fine-tuning involves training the pre-trained language model on a small amount of task-specific data.
- What are some applications of fine-tuning? - Fine-tuning can be used for a wide range of applications, including sentiment analysis, named entity recognition, and text classification.
Fine-tuning examples:
-
Fine-tuning recipe with Parameter efficient finetuning LoRA and evaluation
-
Interactively fine-tune Falcon-40B and other LLMs on Amazon SageMaker Studio notebooks using QLoRA
RLHF: Reinforcement Learning from Human Feedback
- Youtube lecture by Hyung from OpenAI Slides
- Blog by Chip
- Reading notes on RLHF
Reward model (RM): RM is used to model human feedback. Reward model is also a language model except for the last layear is the linear layer that outputs a reward value. Given two completion \(y_{i}\) and \(y_{j}\), objective to model the probability \(p_{ij}\) which denotes the confidence for \(y_{i}\) is better than \(y_{j}\):
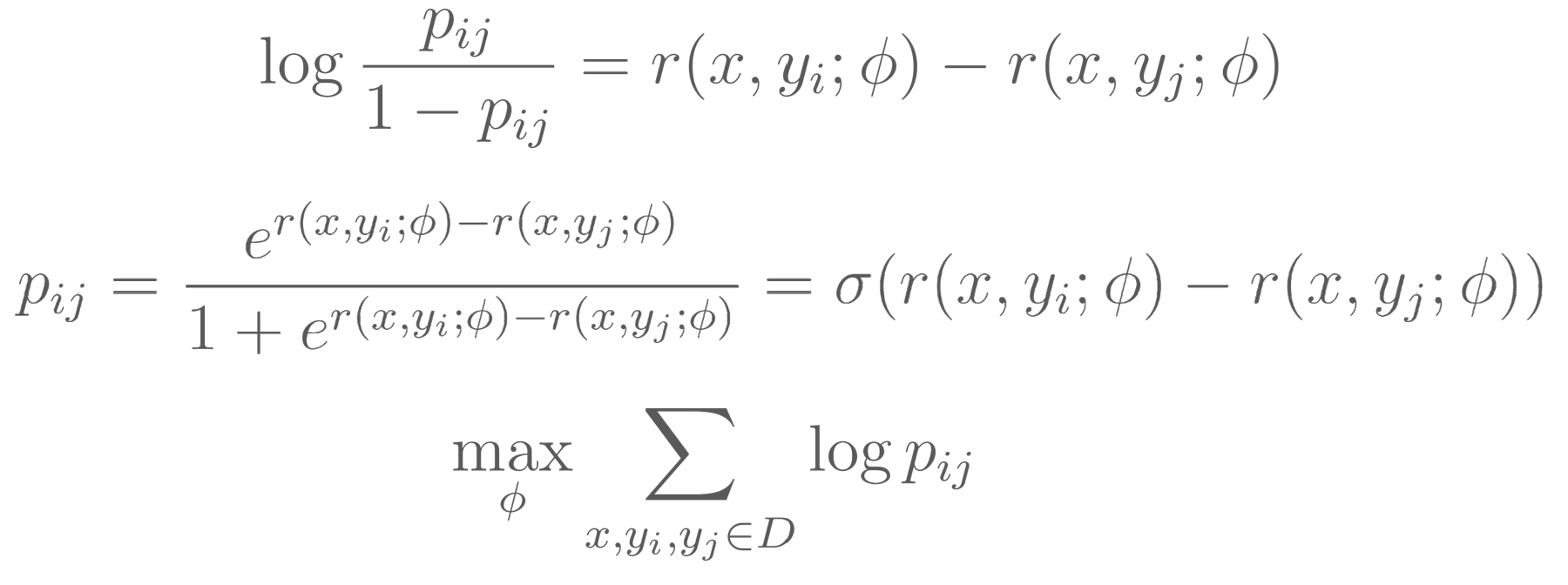
Proximal policy optimization (PPO): Next, we apply reinforcement learning that trains a policy aka language model parameters to generate text with higher reward based on the reward model. It samples many prompts and uses the language model to generate sequence for these prompts. Objective is to maximize the expected reward i.e., weighted summation of completion rewards with weights as the probability of the completion.
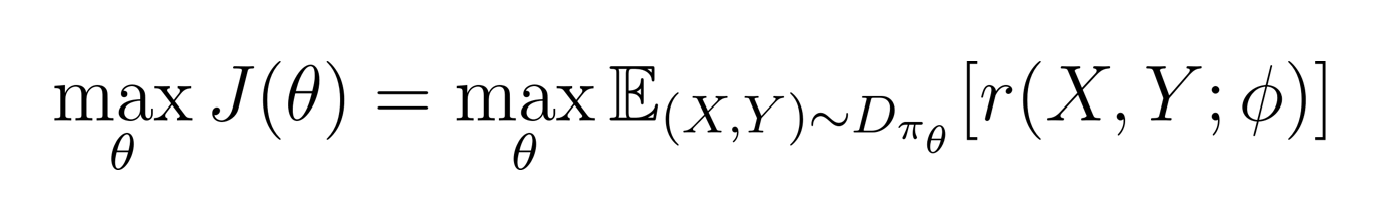
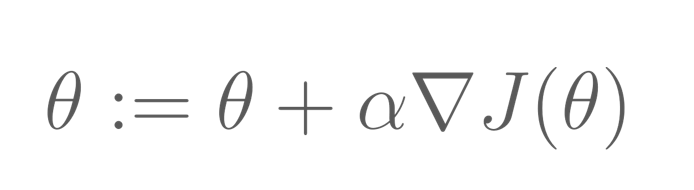
Proximal policy optimization (PPO) is used to compute the gradient. Iterative algorithm like gradient ascend is used to solve the optimization objective.
Steps of policy gradient training steps:
- Initialize parameters of the language model from Supervised finetuned mode
- Samples prompt from dataset, generates sequence for the prompts and current policy
- Calculate reward for the prompt and completion
- Calculate gradients and update the parameters of the language model
Regularization Vanilla policy gradient can over optimize to the Reward model. A per-token KL divergence from SFT distribution penalty added as a regularization. This is to keep some of the variation from SFT model.
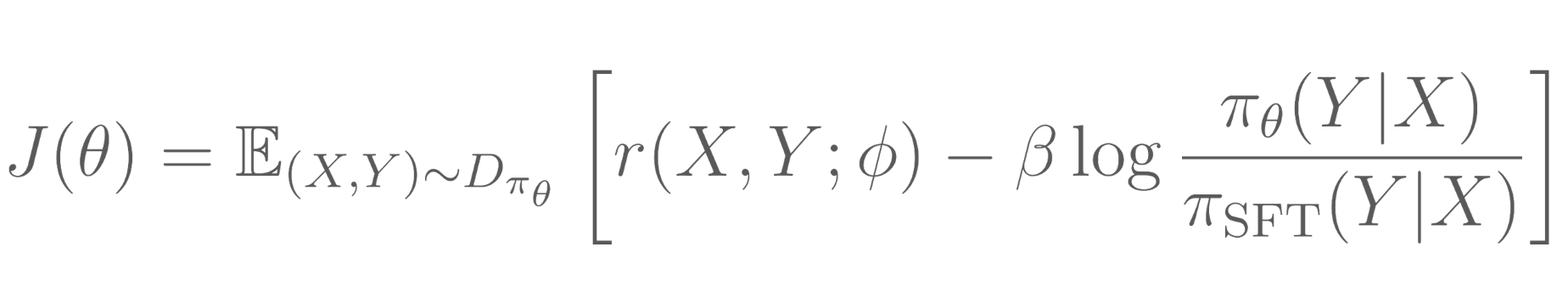
Mixture of expert
Langchain handbooks
- LangChain for LLM Application Development | DeepLearning.ai | Student copy
- LangChain: Chat with Your Data | DeepLearning.ai | Student copy
- LangChain handbook
Retrieval augmented generation (RAG)
- Corrective and self reflection RAG in langchain
- Adaptive RAG with mistral and llamaindex
- Financial query Mixtral model
Online course
- NYU 2023 spring course on Natural Language Processing
- Building Systems with the ChatGPT API | DeepLearning.ai | Student copy
- Full stack’s course on LLM
Evaluation of LLM
Knowledge representation and Hallucination
- Hallucination refers to mistakes in the generated text that are statistically plausible but are in fact incorrect or nonsensical
- Stanford lecture
Application
Select technical concepts related to LLM and Transformer
Byte Pair Encoding (BPE) Byte Pair Encoding (BPE) and SentencePiece are both subword tokenization methods that are used in NLP. BPE is a data-driven method that iteratively replaces the most frequent pair of bytes in a sequence with a single, unused byte. Subword tokenization with BPE helps in effectively tackling the concerns of out-of-vocabulary words. SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabulary size is predetermined prior to the neural model training
Positional embedding Positional embeddings are added to the word embeddings once before the first layer. Each position t within the sequence gets different embedding when t is even then use sine function if t is odd then consine function.