
Fact checking NLP: Selecting the right evidence using BERT
In order to verify a claim, we can utilize a knowledge corpus like Wikipedia. Checking a claim generally involves three steps 1) relevant document retrieval from knowledge corpus, 2) relevant sentence retrieval from the documents, 3) identify whether the claim is supported by the evidence sentences.
In step 1, one process the claim to extract relevant entities which are then used to select Wikipedia documents. Tools for extracting entities include AllenNLP, Stanford OpenIE. MediaWiki API can be used for probing Wikipedia.
In step 2, one needs to select the relevant sentences from the Wikipedia pages as not all the information are needed to verify the claim. An ML model can be trained to select a set of related sentences for a given claim.
In step 3, once a claim is assigned a set of related sentences/evidences, one can train another ML model to classify the label for the claim: supported, refuted or not enough information. Zhou et al. summarize the pipeline in the figure below.
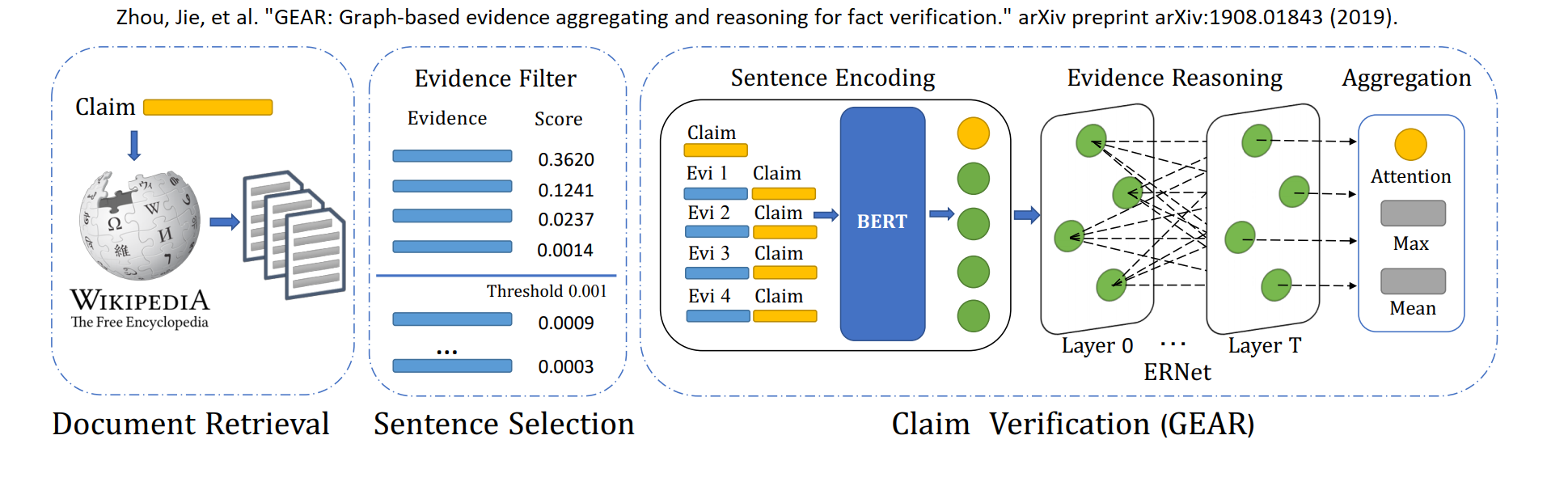
This post will focus on step 2 which identifies the relevant sentences needed to verify a claim. I will describe the work done by Zhenghao Liu et al.. It trains a BERT model to rank related sentences to a claim higher. I have added mixed precision training to the model training.
Mixed precision training
Mixed precision uses 16 bit to store floating point numbers instead of 32 bits. Numerical precision is reduced as a result. Upside is the reduced memory requirement as well as the shorter training time. Point-wise operation like addition, multiplication can still achieve competitive result with reduced precision. However, NN loss functions, activations and weight updates should be stored in higher precision to achieve better performance. NVIDIA’s amp library can automatically set the precision. I added the following codes in the training pipeline to support mixed precision.
# Creates once at the beginning of training
scaler = torch.cuda.amp.GradScaler()
for epoch in range(int(args.num_train_epochs)):
optimizer.zero_grad()
for inp_tensor_pos, msk_tensor_pos, seg_tensor_pos, inp_tensor_neg, msk_tensor_neg, seg_tensor_neg in trainset_reader:
model.train()
# Running forward pass with autocast
with torch.cuda.amp.autocast():
score_pos = model(inp_tensor_pos, msk_tensor_pos, seg_tensor_pos)
score_neg = model(inp_tensor_neg, msk_tensor_neg, seg_tensor_neg)
label = torch.ones(score_pos.size())
if args.cuda:
label = label.cuda()
loss = crit(score_pos, score_neg, Variable(label, requires_grad=False))
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscale gradient and skipping optimizer.step()
scaler.step(optimizer)
# update scaler for next iteration
scaler.update()
Zhenghao Liu et al. use the FEVER dataset that provides Wikipedia documents for a given claim. FEVER dataset contains 185,455 annotated claims with 5,416,537 Wikipedia documents. It is a fact-verification dataset with each claim annotated as SUPPORTS, REFUTES or NOT ENOUGH INFO by annotators. Here is the dataset format:
{'claim': 'Régine Chassagne is Canadian.',
'evidence': [['Régine_Chassagne',
0,
'Régine Chassagne LRB LSB ʁeˈʒin ʃaˈsaːɲ RSB ; born 19 August 1976 RRB is a Canadian multi instrumentalist musician , singer and songwriter , and is a founding member of the band Arcade Fire .',
0],
['Régine_Chassagne', 1, 'She is married to co founder Win Butler .', 0],
['Régine_Chassagne',
0,
'Régine Chassagne LRB LSB ʁeˈʒin ʃaˈsaːɲ RSB ; born 19 August 1976 RRB is a Canadian multi instrumentalist musician , singer and songwriter , and is a founding member of the band Arcade Fire .',
1],
['Régine_Chassagne', 1, 'She is married to co founder Win Butler .', 0]],
'id': 180425,
'label': 'SUPPORTS'}
evidence is a list of sentences from the wikipedia documents with the format: wiki_document_name, sentence/evidence_id, evidence_content, support_flag.
Snapshot of the wikipedia article for the above claim is:
Since a claim can have many sentences / evidences. A classifier can be trained to select a subset of the evidences that are most relevant. In order to do that, a pair-wise dataset is prepared where each claim is followed by relevant evidence. It is referred to as positive example. Conversely, the claim followed by its non-relavant evidence is referred to as negative example. Here is a positive example:
Ireland is a place on Earth surrounded by water. Ireland is separated from Great Britain to its east by the North Channel , the Irish Sea , and St George 's Channel.
A negative example:
Ireland is a place on Earth surrounded by water. As of 2013 , the amount of land that is wooded in Ireland is about 11 % of the total , compared with a European average of 35 % .
BERT model provides the representation for the claim-evidence pair. A learning-to-rank layer maps the representation to a ranking score. It is trained to output high score for supporting evidence and low score for non-supporting evidence. Margin Ranking Loss is used as the loss function. Inference is done by feeding a claim and its evidences without any annotation. If the golden evidences for a given claim appear within the top 5 scores, then it is considered as a successful retrieval. Performance is measured in F1@5, Precision@5 and Recall@5 scores.
Run it on a colab notebook.