
Engineering the Glue: The Rise of Autonomous Harness Engineering
In the rapidly evolving landscape of AI, research suggests that the harness—the “glue” or “plumbing” that determines what an LLM stores, retrieves, and sees—can be as critical as the model itself. A well-engineered harness can account for a 6x performance gap on the same benchmark using the same fixed model weights. Traditionally a manual process of expert trial and error, we are now seeing the emergence of automatic harness engineering, where agents autonomously write, test, and refine their own infrastructure.
The Concept: Agents Building Better Agents
The transition toward autonomous optimization treats harness engineering as a search problem over the space of possible programs. This typically involves a dual-layer architecture:
- The Target (Inner) Agent: The agent being optimized for a specific task.
- The Proposer (Outer) Agent: A high-level coding agent (such as Claude Opus 4.6) that analyzes execution traces and edits the target agent’s “surfaces”—including prompts, tool descriptions, and middleware—to improve performance.
Key Frameworks in Autonomous Evolution
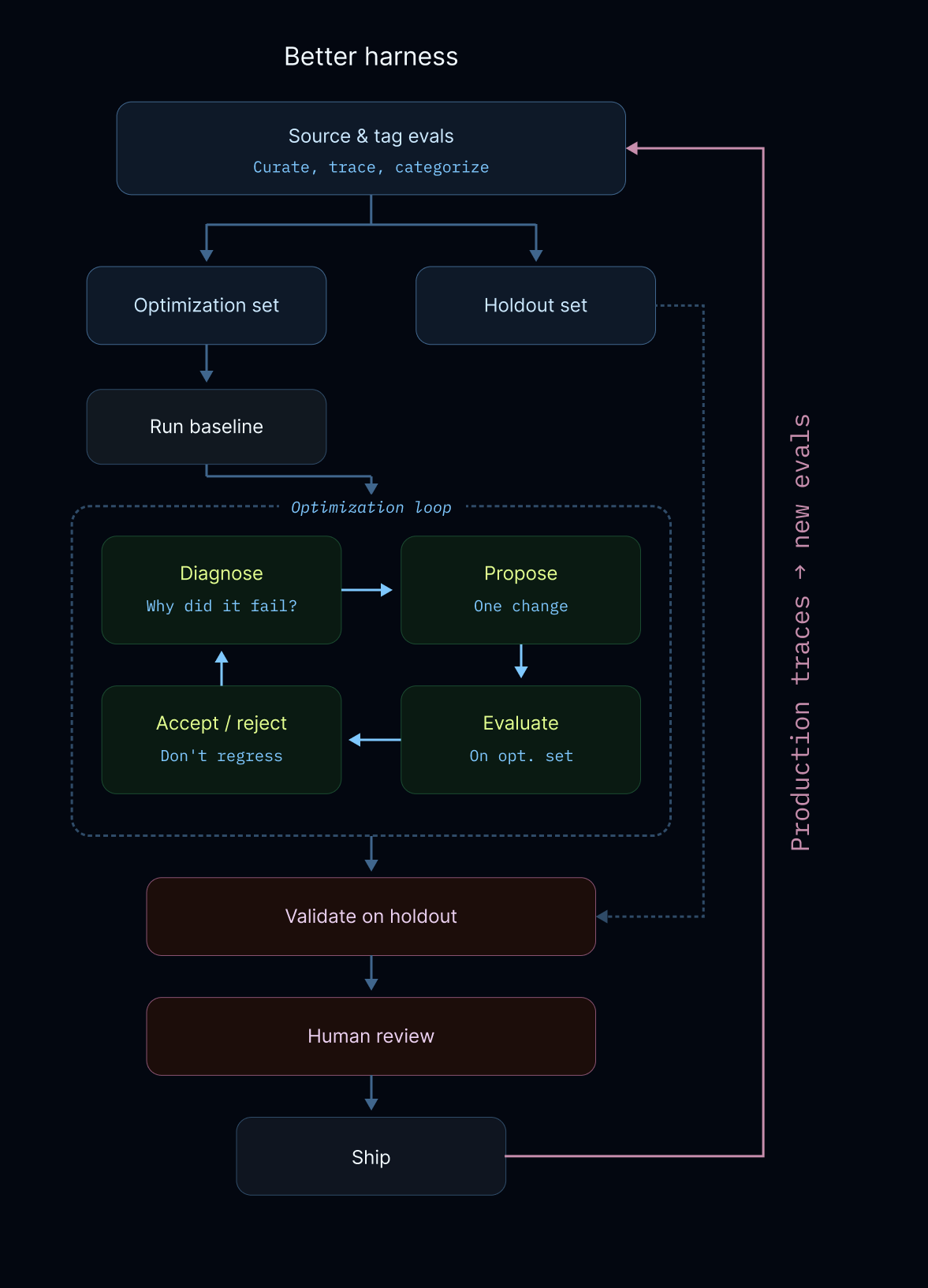
1. Better-Harness: Evals as Training Data
Developed at LangChain, Better-Harness posits that evals are the training data for agents. It utilizes a “hill-climbing” recipe where the system runs baselines, diagnoses failures from execution traces, and experiments with targeted changes. To ensure the system truly learns, it uses holdout sets to verify that optimizations generalize rather than overfit to specific examples.
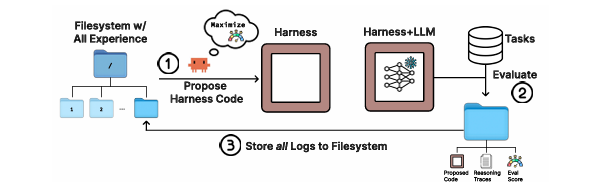
2. Meta-Harness: Filesystem-Based Memory
Stanford’s Meta-Harness addresses the limitations of “memoryless” optimizers by exposing the full history of prior candidates through a filesystem. This allows the proposer to use standard tools like grep and cat to perform causal reasoning over raw execution traces and code, helping it identify why certain changes caused regressions. Meta-Harness successfully discovered a harness that ranked #1 among Haiku 4.5 agents on the competitive TerminalBench-2 leaderboard.
3. AutoHarness: Code as a Verifier
Google DeepMind’s AutoHarness focuses on “code as harness,” where an LLM synthesizes a program to act as a rejection sampler or policy. In the TextArena domain, this framework allowed a smaller model (Gemini-2.5-Flash) to prevent 100% of illegal moves in 145 different games, enabling it to outperform larger models like Gemini-2.5-Pro.
4. RoboPhD: Elo-Based Competition
RoboPhD introduces a validation-free evolution strategy. Instead of splitting a budget between training and validation, it uses Elo-based competition on training data to simultaneously evaluate and rank agents. A unique contribution is the development of self-instrumenting agents, where agents evolve their own print() diagnostics to provide increasingly informative feedback for their evolutionary successors.
5. KernelEvolve: Optimizing to the Silicon
At the infrastructure level, Meta’s KernelEvolve applies these agentic techniques to low-level hardware kernels. By treating kernel optimization as a search problem, it compressed weeks of expert work into hours, achieving a 60% inference throughput improvement for the Andromeda Ads model on NVIDIA GPUs.
The Optimization Loop
While implementations vary, these systems generally follow a shared feedback-driven cycle:
- Sourcing & Tagging: Curating high-quality evals from hand-written examples or production traces.
- Autonomous Diagnosis: Using agents to “read” execution logs to understand specific failure modes (e.g., infinite loops or tool misinterpretations).
- Targeted Experimentation: Proposing atomic changes to the harness code to fix discovered errors.
- Validation: Checking changes against optimization and holdout sets to ensure net performance gains without regressions.
The Future of Autonomous Systems
The ultimate goal of these frameworks is recursive self-improvement. By automating the “plumbing” of AI, we move toward a world where agents not only solve tasks but also continuously build the more efficient, reliable versions of themselves.
References
- Better-Harness: Better Harness: A Recipe for Harness Hill-Climbing with Evals
- DeepAgents (LangChain): deepagents/examples/better-harness
- KernelEvolve (Meta): KernelEvolve: How Meta’s Ranking Engineer Agent Optimizes AI Infrastructure
- Meta-Harness (Stanford): Meta-Harness: End-to-End Optimization of Model Harnesses
- AutoHarness (Google DeepMind): AutoHarness: Improving LLM Agents by Automatically Synthesizing a Code Harness
- RoboPhD: RoboPhD: Evolving Diverse Complex Agents Under Tight Evaluation Budgets
- AutoResearch (Karpathy): GitHub - karpathy/autoresearch
- MultiAutoResearch (Burtenshaw): GitHub - burtenshaw/multiautoresearch