
Effective Reinforcement Learning
Reinforcement learning is prone to noise. It is harder to reproduce an experiment that trains a reinforcement learning agent. An agent can produce different results despite using the same seed for random number generator. Primary reasons are the following
- Stochastic environment is stochastic. The same set of actions may lead to different states of the world and rewards
- Agents with different initialization of weights produce different results
- Different choice of hyperparameters produce different results
- Distributed training of the agent
- Non-determinism from the ML framework
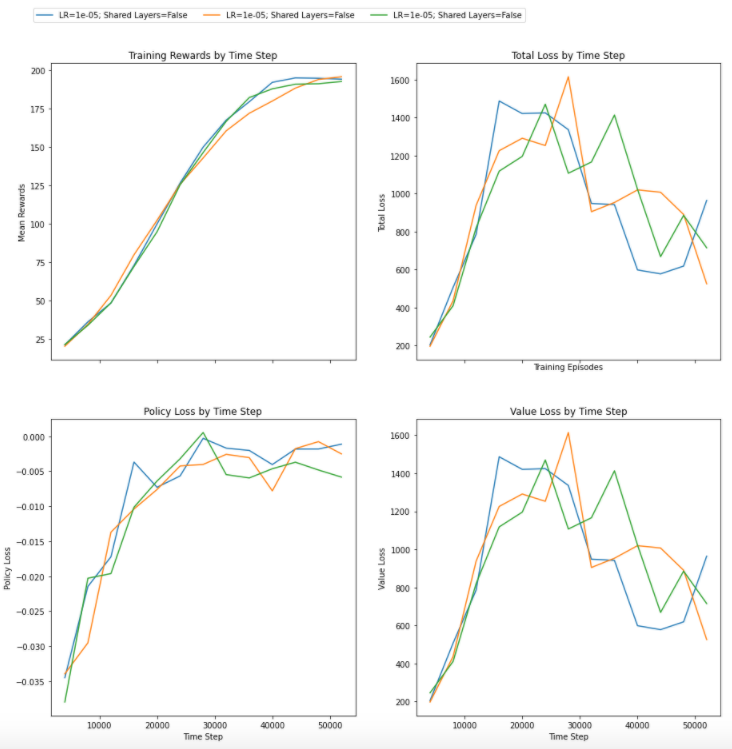
Noise in the agent’s output impacts any meta-learning. I will demonstrate one example of noise when several parameters are tuned for cartpole reinforcement learning agent.
Noise in the agent is displayed in the picture where the agent produces different results for the same set of action and hyperparameters.
Code
For a code example, access the jupyter notebook here.
How to address noise
There have been some proposals in the literature that aim to deal with a noisy evaluation function during metalearning. Here RL agent is the noisy evaluation function and optimal parameter search is the metalearning.
Rakshit, Pratyusha, Amit Konar, and Swagatam Das.
"Noisy evolutionary optimization algorithms–a comprehensive survey."
Swarm and Evolutionary Computation 33 (2017): 18-45.
One way to deal with noise in meta-learning is penalize parameters that produce output with high uncertainty or variability. An algorithm implementing this approach is following:
- Set value of \(N\) as \(N\) = \(NUM\_SAMPLES\)
- Run all trials \(N\) times.
- Collect noisy feedbacks for \(i\)th trial: \(f_{i}\)
- Sample a new trial based on: \(\operatorname*{argmax}_i \bar {f_{i}} + \frac {\sqrt{N}}{\sigma}\)
Another approach is to resample parameters with higher uncertainty to reduce noise and increase quality of the meta-learner. Research work studying this approach is the following:
Lucas, Simon M., Jialin Liu, and Diego Perez-Liebana. "The n-tuple bandit evolutionary algorithm for game agent optimisation."
2018 IEEE Congress on Evolutionary Computation (CEC). IEEE, 2018.