
Amazing Ai
Meta-Learning Representations for Continual Learning
Javed, Khurram, and Martha White. "Meta-learning representations for continual learning." Advances in Neural Information Processing Systems. 2019.
Authors propose to address catastrophic forgetting when learning multiple tasks. Tasks interfere with each other. When such forgetting appear
- Correlated inputs
- Dense input
- Global and greedy update
They propose to create task representation, called RLN. They propose a
separate prediction model, called PLN. These two steps in combination constitute a learning model that is able to generalize over multiple tasks. RLN is fixed once representation is learned. Only PLN network is updated when continual learning starts.
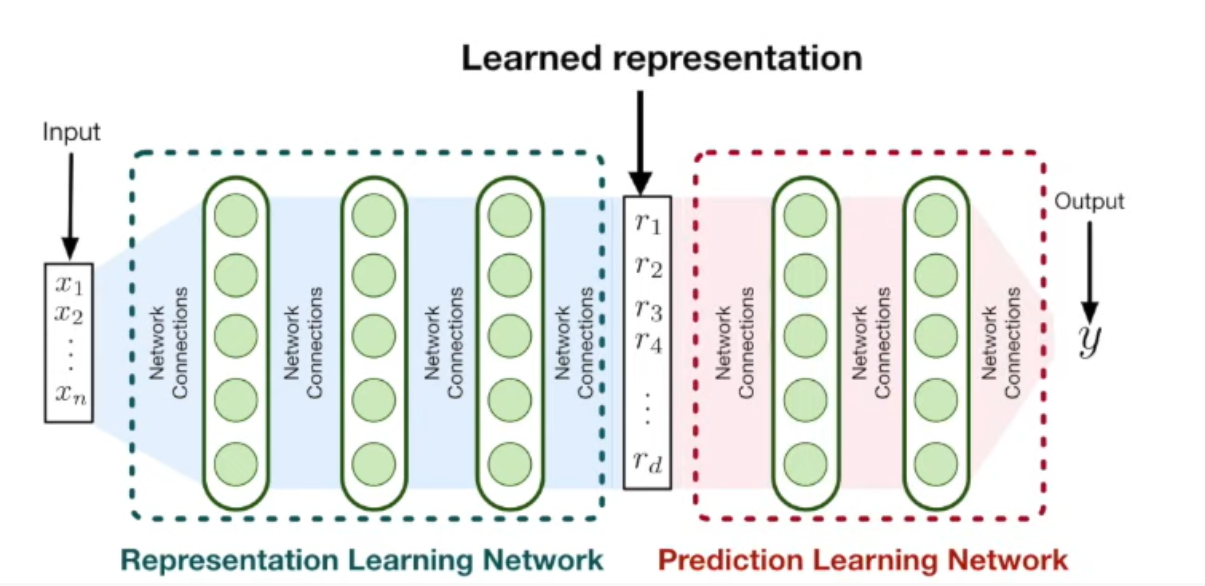
The authors train these two networks with the objective of reducing interference among tasks. They select a set of correlated samples and a set of random samples. Networks trained on the correlated samples should provide similar performance on the random subset of samples. Loss function measures the performance degrade on the random samples.
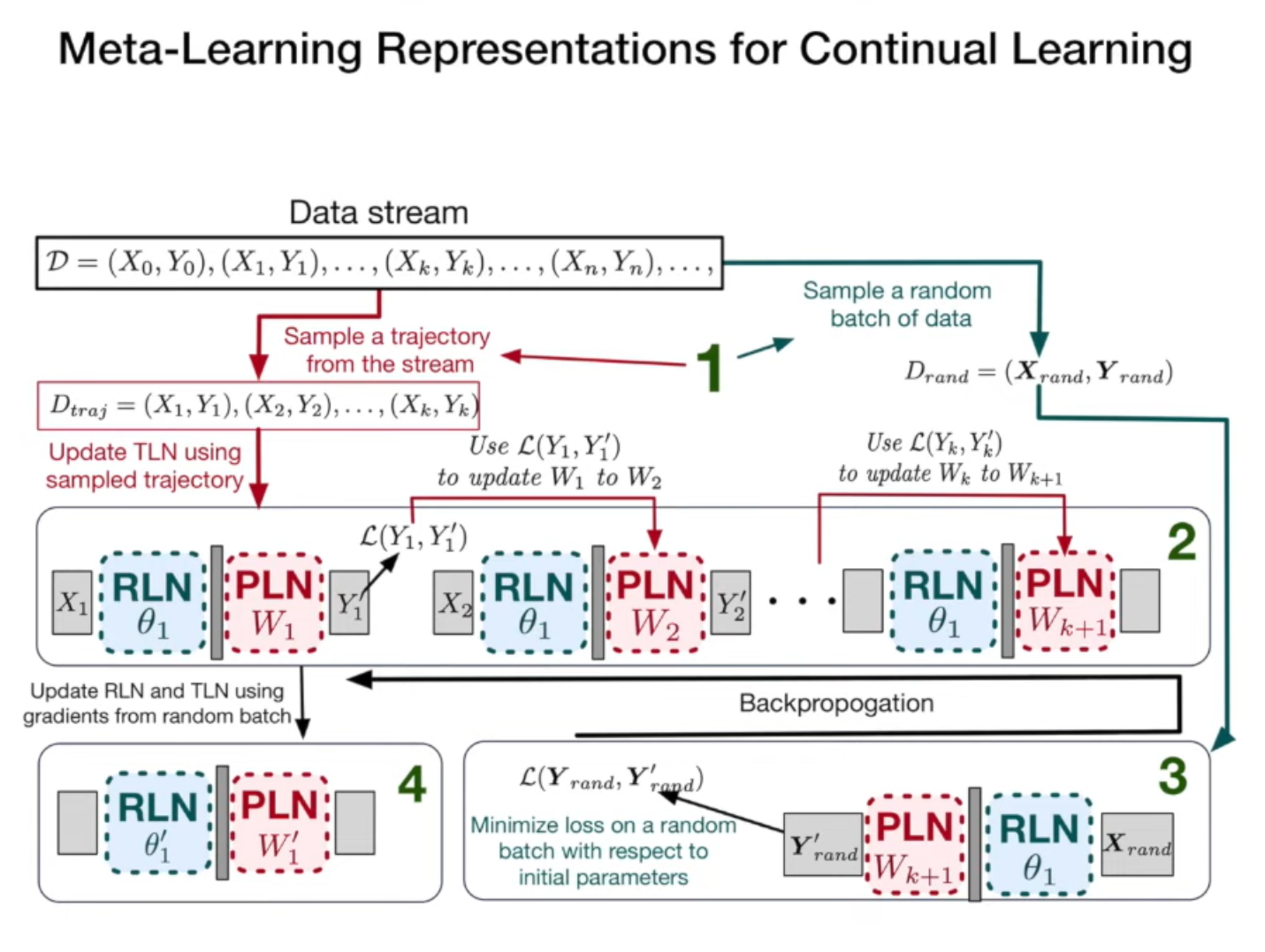
The image above shows one update in the meta learning. RLN is initialized with \(\theta_{1}\) and PLN with \(W_{1}\). Through gradient descend, PLN is updated k times where k is the number of samples. Then a random subset of samples are drawn and loss is calculated on the random subsets based on the network’s prediction. Gradient descend is calculated on the initial parameters \(\theta_{1}\) and \(W_{1}\) which are then updated. Similar meta learning steps are repeated many times.
Improving Generalization in Meta Reinforcement Learning using Learned Objectives
In a typical RL problem, a new RL agent is initialized from scratch, placed and trained in a new environment using a human-engineered learning algorithm. The authors propose that the agent should be meta trained first i.e.,
Meta-Training: It will improve the learning algorithm by using it in one or multiple environments. It should be updated so that it works better when an RL agent uses it to learn (increase reward income).
Meta-Training should be followed by the regular meta-testing RL step where an agent is initialized and trained in a new environment using a learning algorithm that is learned using Meta-Training.
The proposed learning algorithm as an objective function \(L_{\alpha}\) that is parameterized by a neural network with parameters \(\alpha\). LSTM is used as the objective function. Most of the existing works use Policy Gradient as the objective function.
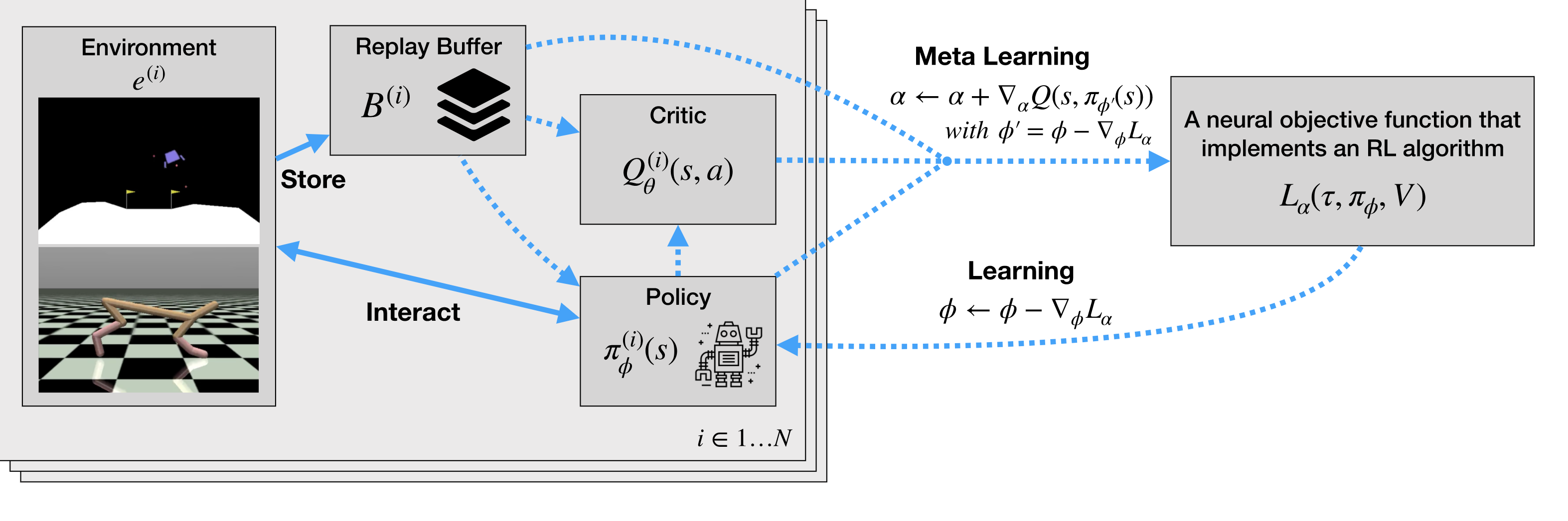
Intuitive workflow:
[1] Agents interact with their environment according to their own current policy. The collected experiences are stored in the replay buffer.
[2] Replay buffer can be used to train a separate neural network, critic, that can estimate how good it would be to take a specific action in any given situation.
[3] MetaGenRL uses the objective function L to change the policy. Then, the updated policy outputs an action for a given situation which is evaluated by the critic measuring how good this action is.
[4] Based on this information, one can update the objective function to produce better actions in the future when used as a learning algorithm (‘meta-learning’).
[5] It is done with a second-order gradient, backpropagating through the critic and policy into the objective function parameters.
[6] Each policy is updated by differentiating \(L_{\alpha}\). On the other hand, the critic is updated using the usual Temporal Difference error. \(L_{\alpha}\) is meta-learned by using second-order gradients by differentiating through the critic.
META-LEARNING ACQUISITION FUNCTIONS FOR TRANSFER LEARNING IN BAYESIAN OPTIMIZATION
The authors address how to transfer learning from one meta-learning to the next meta-learning. If the meta-learning search can be biased in the right direction, it has the potential to save time. Authors have studied Bayesian optimization as the meta learning algorithm. Their proposal include:
- There is a notion of source tasks and target task (e.g., Hyperparameter search on a set of 30 datasets to fasttrack search on a given dataset)
-
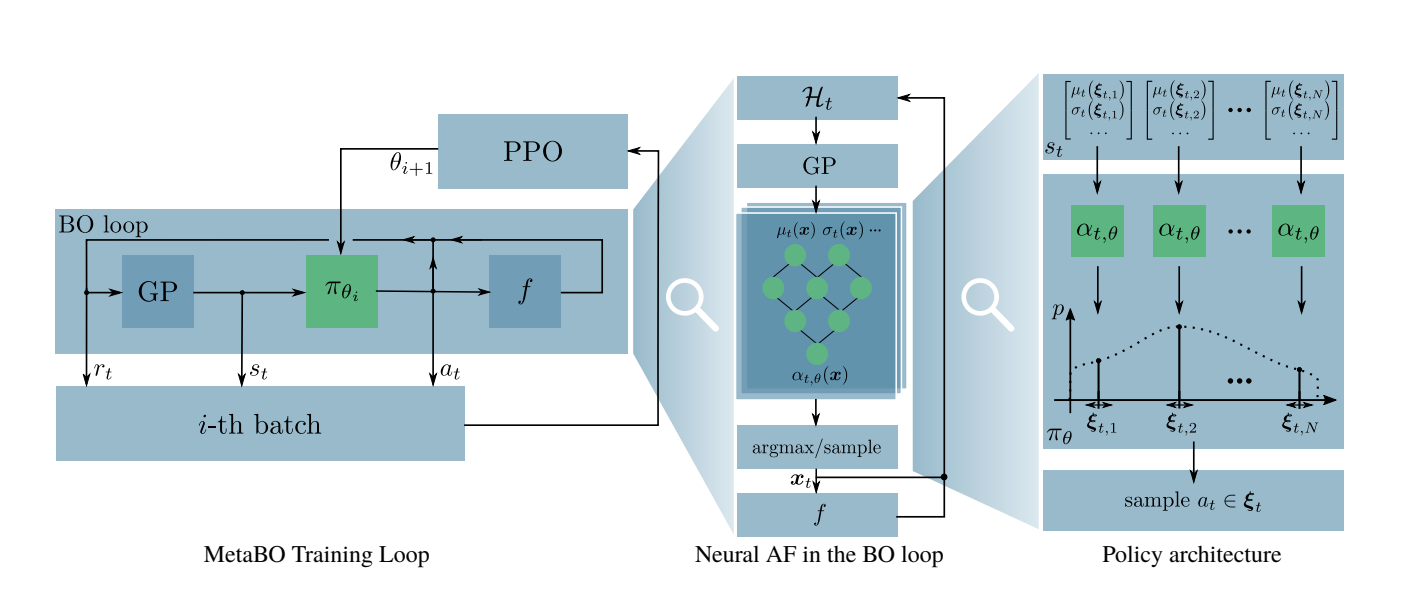
MetaBO is trained on the set of source tasks
- Train a neural network as Acquisition Function (AF) on the datasets that consists of previous meta-learning outcomes
- In each iteration of Bayesian Optimization, a task is randomly picked and update Neural AF weights based on learning from the task.
- It runs some initial non-greedy evaluations to learn about target objective funtion.
- Use Reinforcement learning to facilitate training of the neural network to approximate gradient of the black-box optimization function
- Use the neural network as the acquisition function to identify the next potential point to evaluate
Defending Against Neural Fake News
Zellers, Rowan, et al. "Defending against neural fake news." Advances in Neural Information Processing Systems. 2019.
Authors provide a threat model for fake news detection that utilizes the following
- Detect fake news by utilizing a fake news generator
- Look for artifacts like out-of-distribution sampling left by a generator
- Question: Is a generated news article always a fake news?
As a solution, the authors propose a transformer-based language model, called Grover. It is trained on a huge corpus of text found online. The language model is specially trained to generate news article.
To detect fake news, the authors perform binary classification that uses training set consisting of both real and fake news. Rather than training a classifier from scratch, they extract features / hidden state from a pretrained language model e.g., Grover. Features are fed to a fully-connected layer to make the final classification.
Some artifacts for fake news found by the authors:
- The probability of observing a human-written article where all tokens are drawn from the top-p% of the distribution is quite low. Language models typically perform inference this way.
- As the generated sequence length increases, out of distribution tokens appear more commonly
DeepHyper: Asynchronous Hyperparameter Search for Deep Neural Networks
Balaprakash, Prasanna, et al. "DeepHyper: Asynchronous hyperparameter search for deep neural networks." 2018 IEEE 25th international conference on high performance computing (HiPC). IEEE, 2018.
DeepHyper is a scalable hyperparameter search library for high performance computing systems. The authors propose an asynchronous model based Bayesian Search (AMBS) which works in the following ways:
-
Contains a master and a set of workers. The master generates the hyperparameter configurations and the works evaluate them and report the validation errors back to the master.
-
As soon as an evaluation is completed, the validation error is used to bias the search toward more promising regions of the search space using a surrogate model. They considered Random forest, Gaussian process as the surrogate models among others.
-
Lower confidence bound (LCB) is used as the acquisition function in other words, to acquire next sample point to evaluate. \(LCB(x) = \mu(x) − \lambda ∗ \sigma(x)\). As \lambda increases, the search focuses toward pure exploration, and points are chosen based on their potential to improve the performance.
Key findings of the paper are the following:
- Search comparision
- For the mnistmlp, mnistcnn, and gcn, AMBS obtains very good hyperparameter configurations—more than 50% of the configurations obtain accuracy higher than 80%.
- It comes with an exception is that cifar10cnn benchmark, where neither of the search methods obtain hyperparameter configurations with more than 80% accuracy.
- Surrogate model comparison
- The authors observe that Random Forest outperforms Extra Trees, Gradient Boosted Regression Trees, and Gaussian Processes on all but one benchmark which is GCN, where Extra Trees is slightly better than Random Forest.
-
Scaling on theta:
-
AMBS is able to generate enough configurations and maintain the worker utilization to over 90% for the cifar10cnn hyperparameter searches since the variance of compute time is high.
-
As a partial remedy to improve the performance of AMBS at scale, they have evaluated the same search at 1,024 nodes with a batch generator function. The generator divides a request high number of new hyperparameter configurations down into batches of a given size (sample default 20).
-
The number of models with greater than 50% accuracy increases from 1 to 19 as we scale with AMBS from 8 to 64 nodes. because the search converges toward configurations with few tens of training epochs that finish faster, while the RS method uniformly samples configurations over a wide range and thus take longer to finish.
-
OpenAI scaling laws
Summary of the scaling laws:
- Data requirements grow very slowly as
D ∼ C^{0.27}with available compute. - When more computational budget C is available, it pays off to spend it on larger models.
N ∝ C^0.73 - Larger models are sample efficient
B ∝ C^0.24 - In practice, fewer optimization steps are needed when more compute is available
S ∝ C^0.03
To review:
Zero-day attack detection
Intrusion detection applies machine learning to detect anomalious access. Here are few recent works of how machine learning can help.
Tang et al. apply encoder-decoder network to reconstruct the sequence of tokens. They measure the difference in BLEU score to classify anomaly.

Haider et al. apply fuzzy rough set attribute reduction (FRAR) method to construct features and apply Gaussian mixture model (GMM) to detect anomaly.

(In progress) [Automatic training and hyperparameter tuning for anomaly detection]
- Malware samples change frequently. So detection tools should be frequently trained with an optimial set of hyper-parameters to achieve the desired performance.
- Publicly available EMBER Dataset
- AutoGluon and NNI Automatic machine learning
- Extract 2381 features using Library to Instrument Executable Formats (LIEF): https://lief.quarkslab.com/