
AI Agent Security
Autonomous AI agents — from warehouse robots to financial trading bots and conversational assistants — have become ubiquitous. In 2025 and early 2026, the research community and industry accelerated efforts to understand and defend against risks unique to these agents. Alongside academic papers, we’ve seen detailed industry case studies such as AWS’s multi‑agent penetration‑testing architecture and Anthropic’s Mozilla partnership, which together demonstrate both the power and the pitfalls of deploying agentic systems in the wild. This post walks through the most important findings, frameworks, and best practices that practitioners should know today.
🔍 What is an AI Agent?
An AI agent is a software system that perceives its environment, makes decisions, and takes actions to achieve goals. Agents range from simple rule-based bots to complex multi‑modal systems trained on large models.
Security concerns arise when agents operate with high levels of autonomy, access sensitive data, or interact with other systems — essentially anytime they are “trusted” to act without human oversight.
AI Agent Security Workflow
Workflow of securing AI agents has these phase
- Design: define goals, threat model risks, constrain with least privilege and guardrails
- Evaluate before release: Run security evaluation (injection, tool misuse, memory contamination.
- Monitor deployment: Enforce runtime policy enforcement, record telemetry and continous red-teaming/regression testing
- Incident response and improve: Detect drift, vulnerabilities, respond to incident and feed findings back into redesign and continously harden system.
📚 Key Research Highlights (2025–2026)
- Formal threat taxonomies
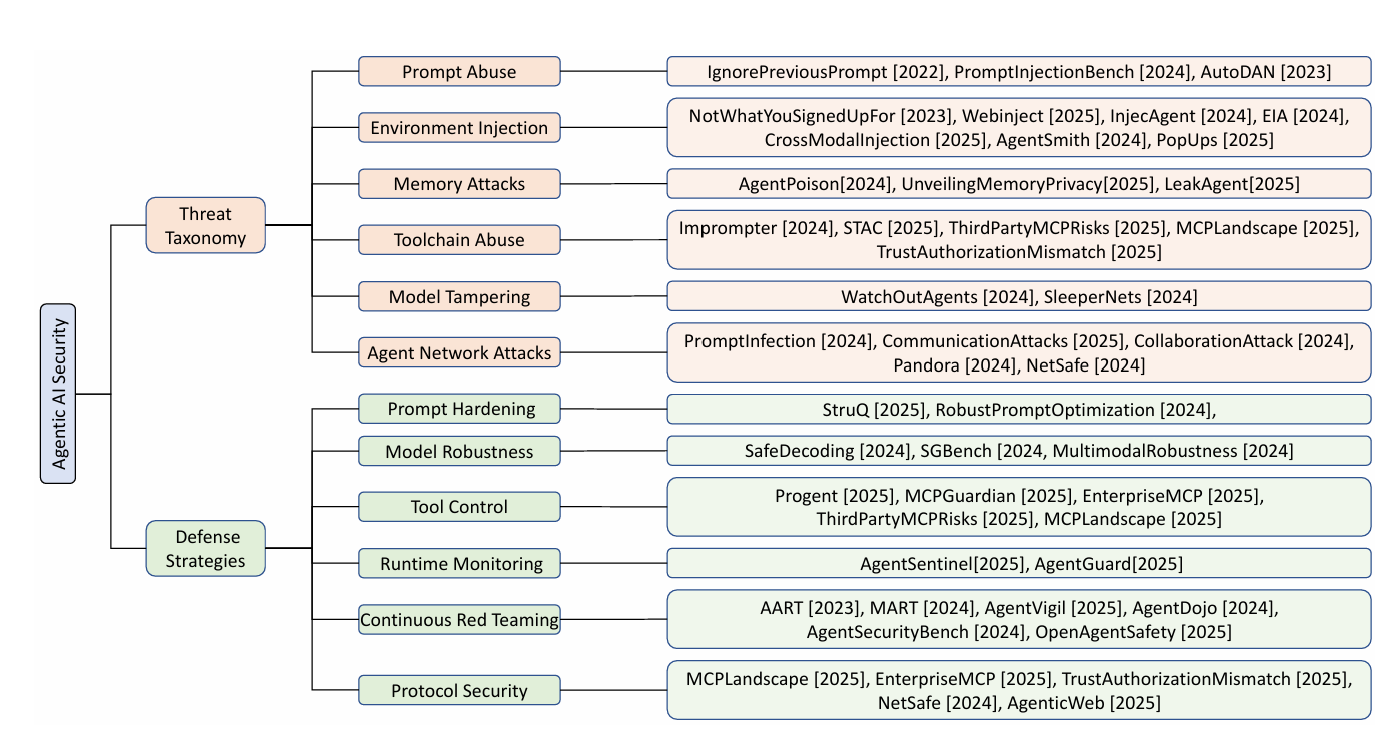
- Deng et al. (2026) introduced a structured classification of agent attacks:
- Adversarial manipulation (poisoning inputs or rewards)
- Manipulation of internal state (memory tampering)
- Supply‑chain abuses (malicious plugins or model weights)
- Their framework underpins later work on defenses.
- Deng et al. (2026) introduced a structured classification of agent attacks:
- Robust reward design
- Studies from MIT and DeepMind (2025) demonstrated that agents with distribution‑aware reward functions resist “specification gaming” better and are harder to subvert via crafted environments. Epistemic Traps: Rational Misalignment Driven by Model Misspecification
- Runtime monitoring & introspection
- A 2026 paper proposed lightweight introspective agents that continuously audit their own decisions against logged policies, outperforms baseline agents. Exploration Through Introspection: A Self-Aware Reward Model
- Secure multi‑agent coordination
- Another work shows cryptographically authenticated communication between agents, preventing rogue actors in decentralized fleets (e.g., drones or autonomous vehicles). Beyond Context Sharing: A Unified Agent Communication Protocol (ACP) for Secure, Federated, and Autonomous Agent-to-Agent (A2A) Orchestration
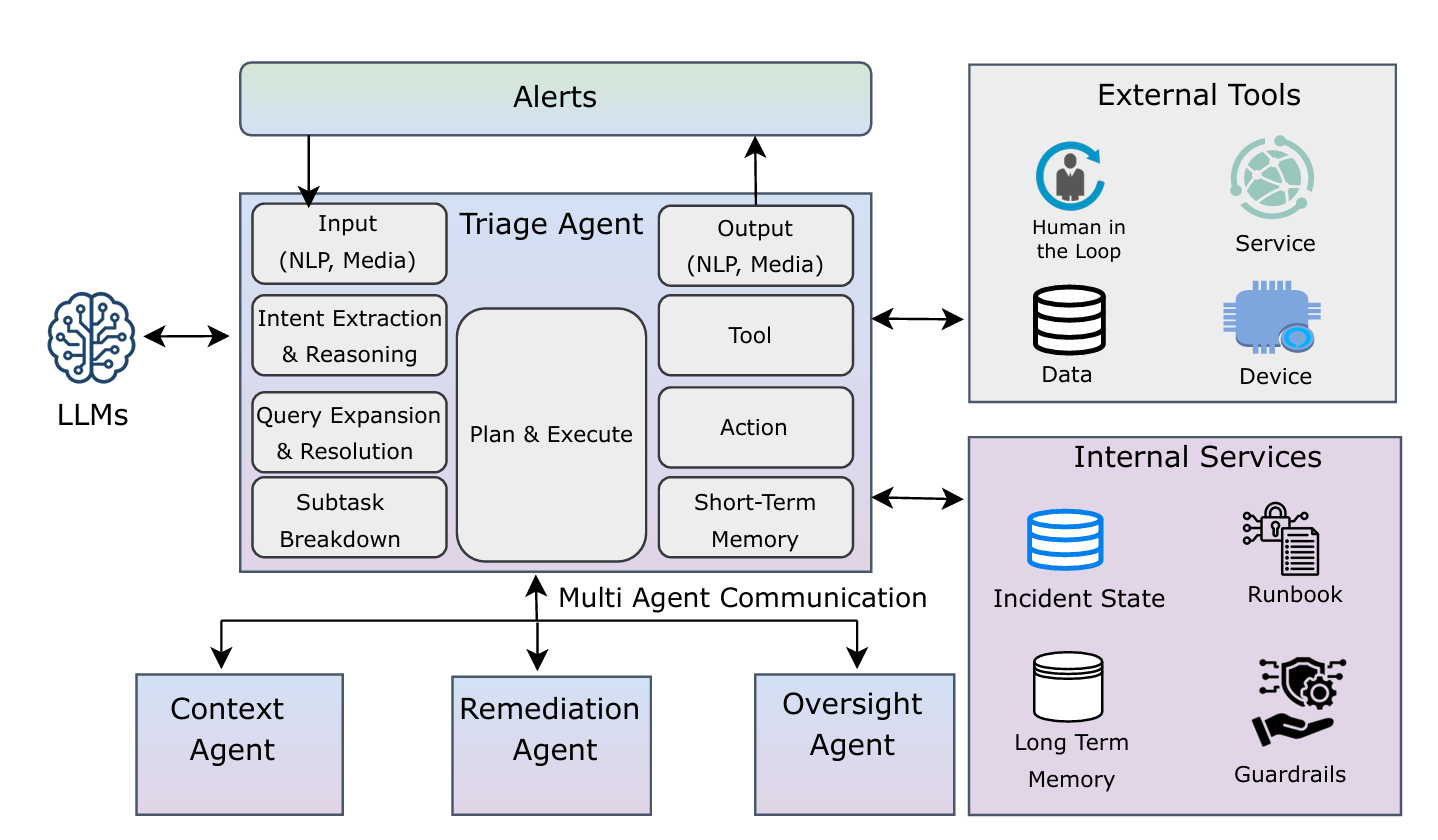 Human Society-Inspired Approaches to Agentic AI Security: The 4C Framework
Human Society-Inspired Approaches to Agentic AI Security: The 4C Framework
As an example of multi-faceted responsibility in AI systems, consider a triage agent monitoring alerts, a context agent may pull logs and context, then a remediation agent proposes a set of actions, and an oversight agent ensure approvals before any sideeffects.
- Multi‑agent vulnerability hunting at scale
- An AWS Security Blog post (Feb 2026) described the Security Agent: a multi‑agent architecture for automated penetration testing. Specialized scanners perform baseline analysis and a hybrid managed/guided exploration phase dispatches swarm workers across risk categories. Findings are validated with assertion‑based checks and CVSS scoring; benchmark results on CVE Bench reached 92.5 % attack success with grader feedback and 80 % in realistic settings. The paper also highlights budget trade‑offs (breadth vs depth) and the need for repeatable runs to overcome LLM non‑determinism.
- AI‑enabled vulnerability research
- Anthropic’s collaboration with Mozilla (Mar 2026) used Claude Opus 4.6 to scan Firefox for CVEs, yielding 22 reports—14 high‑severity—that were fixed in Firefox 148. The effort showed that models can rapidly identify bugs and even craft primitive exploits, prompting a new paradigm of defender‑driven “patching agents” equipped with task verifiers. The partnership emphasized providing maintainers with minimal test cases, proofs‑of‑concept, and candidate patches as industry best practices.
Core Techniques from Industry Case Studies
- LLM‑augmented authentication – AWS’s Security Agent uses an intelligent sign‑in component that combines LLM reasoning with deterministic logic and browser automation to locate and exercise credentials across varied app architectures.
- Hybrid scanning workflow – baseline scanning is performed by parallel network and code scanners, followed by a two‑phase exploration (managed static tasks and guided context‑driven exploration) orchestrating a swarm of specialized agents.
- Assertion‑based validation & CVSS scoring – candidate findings are vetted through deterministic validators and LLM‑guided exploit attempts, then scored using the Common Vulnerability Scoring System.
- Budget‑aware exploration – balancing breadth‑first vs depth‑first search strategies and rerunning tests to mitigate LLM nondeterminism are central to maximizing coverage under limited compute.
- Model‑driven vulnerability hunting – Anthropic’s work began with training‑set sanity checks against historical CVEs and then used Claude to generate crashing inputs across thousands of C++ files, rapidly surfacing real bugs.
- Human‑AI collaboration for triage – the partnership set up a workflow for bulk submission of crash reports, with Mozilla advising on which cases warranted security filings and how to accompany them with test cases and patches.
- Task verifiers for patching – agents proposing fixes rely on auxiliary tools to automatically re‑test for the original bug and run regression suites, greatly improving patch reliability.
- Exploit generation evaluation – to understand offensive capabilities, Anthropic tasked the model with turning bugs into primitive exploits, running them in sandboxed environments and measuring success rates.
🛡 Industry Best Practices
-
Zero‑trust architecture for agents
Treat every agent, even “internal,” as potentially hostile. Limit capabilities with RBAC and network segmentation. -
Immutable models & package signing
Use signed model checkpoints and container images; verify signatures at load time to prevent supply‑chain compromises. -
Encrypted state and memory
Protect agent internals with hardware enclaves (e.g., Intel SGX, ARM TrustZone) or VM‑level encryption. -
Continuous red‑teaming
Organizations like Google DeepMind and OpenAI now run automated “agent pentests” that fuzz inputs, modify reward signals, and inject adversarial examples regularly. -
Explainability for security audits
Maintain logs of decision rationale. Explainable agents enable faster forensic analysis after an incident. -
Assertion‑based validation
As demonstrated by AWS Security Agent, use structured assertions (natural‑language checks encoded by experts) and dual validation strategies (deterministic + LLM re‑tests) to weed out false positives in automated findings. -
Collaborate with maintainers
When agents surface vulnerabilities (Anthropic–Mozilla case), supplement reports with minimal test cases, proofs‑of‑concept, and candidate patches. Transparent, cooperative disclosure accelerates fixes and builds trust. -
Use task verifiers for patching
Equip patch‑generating agents with verifiers that test for vulnerability removal and regression across the codebase; this technique improves patch quality in real‑world evaluations.
🧠 Lessons Learned
-
Attack surfaces grow with autonomy.
The more an agent interacts or learns, the more avenues attackers have. Don’t deploy agents with broad internet access or unchecked learning unless absolutely necessary. -
Security and safety are inseparable.
Efforts to align agents with human values (e.g. reward shaping) often double as defenses against manipulation. -
Continuous monitoring beats one‑off certification.
Agents evolve — so must your defenses. Build telemetry and alerting from day one. -
Collaboration is key.
The 2026 AgentSec workshop hosted by NIST pushed for shared threat databases and red‑team results; adopt their MITRE‑style matrix.
✅ Practical Checklist for Deploying Secure Agents
- Define and limit permissions via least privilege.
- Sign all code/models and verify at runtime.
- Audit training data for poisoning.
- Instrument agents for self‑monitoring and log all actions.
- Apply regular adversarial tests (internal + external).
- Keep humans “in the loop” for high‑risk decisions.
- Update and patch agents — models, frameworks, and dependencies.
🔮 Future Directions
-
Regulation & standards:
Governments (EU’s AI Act 2024) are beginning to require agent security audits. -
Automated incident response:
Research in 2026 explored agents that can quarantine or rollback other agents when compromise is detected. -
Cross‑organization threat sharing:
Expect industry‑wide consortia to publish attack patterns and mitigations, similar to CVE for software.
As a final thought, securing AI agents isn’t a one‑time task; it’s an ongoing discipline that must evolve with the agents themselves. By staying abreast of the latest research and embedding defenses into the development lifecycle, we can reap the benefits of autonomy without falling prey to its risks.